심층 학습 가이드
AI 코딩은 실패 테스트부터 | RED 없이 고치면 감으로만 통과한다
재현 문장, 실패 로그, 최소 GREEN, 통과 후 리팩터까지
- 핵심 주제
- AI 코딩 검증 루프
- 예상 시간
- 5분
- 업데이트
- 2026.04.26
- 키워드
- AI 코딩 테스트 · RED GREEN REFACTOR · 실패 재현
AI 코딩에서 가장 위험한 순간은 코드가 빨리 나오는 순간입니다. 모델이 빠르게 코드를 내놓으면 「일단 된 것 같다」고 느끼기 쉽습니다. 테스트가 없으면 그 코드는 동작하는 코드가 아니라 동작한다고 믿고 싶은 코드입니다.
이 글의 방향은 단순합니다. AI에게 구현을 맡기기 전에 실패를 먼저 재현합니다. 실패 테스트가 있어야 AI가 어디까지 고쳐야 하는지 알 수 있고, 사람이 결과를 감이 아니라 증거로 판단할 수 있습니다. 읽는 데는 약 10분이면 됩니다. 설정 시간보다 습관이 본체입니다. 한 이슈마다 RED 로그를 남기는지만 지켜도 AI 코딩의 사고율이 눈에 띄게 떨어집니다.
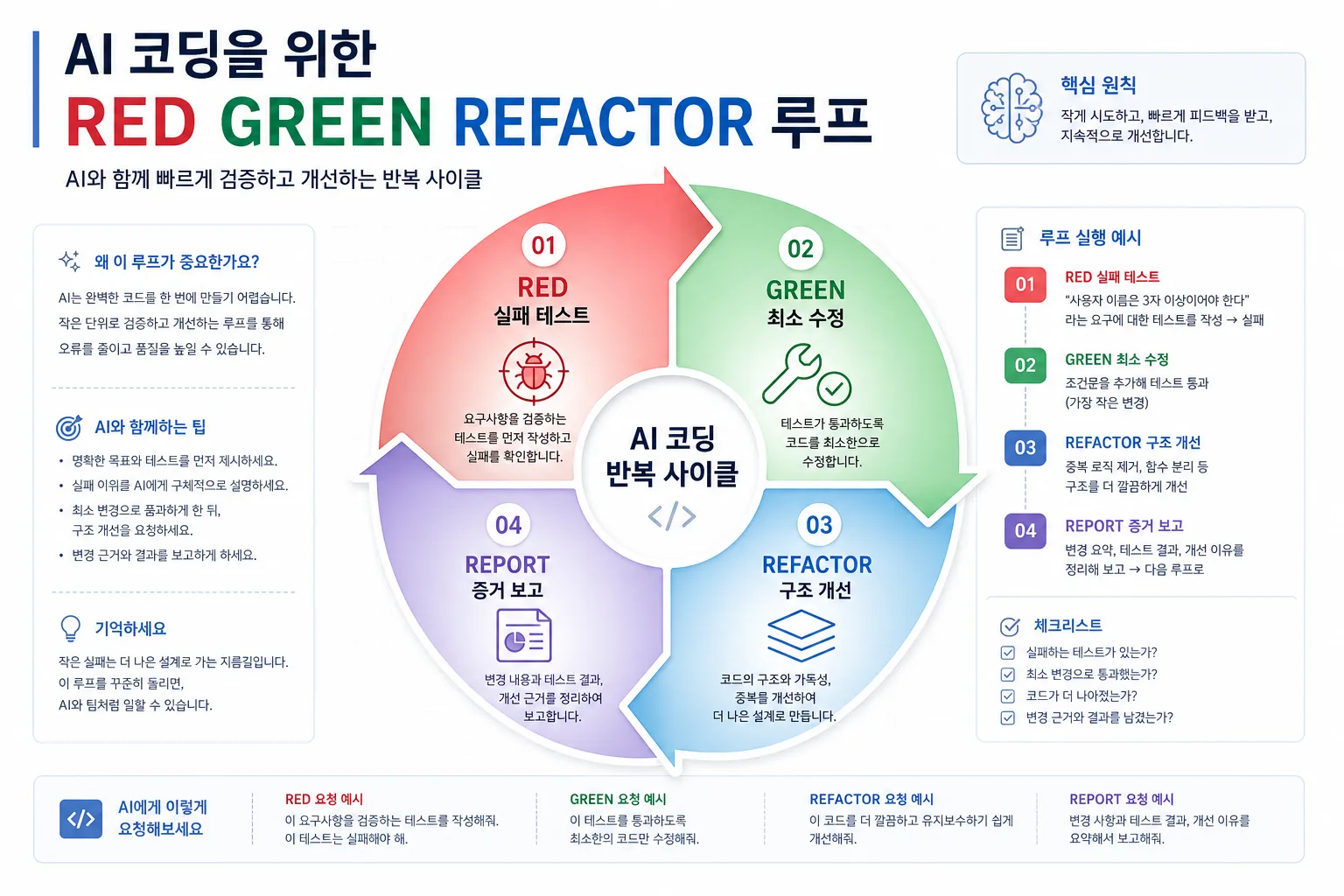
막히는 지점은 대개 세 곳입니다. 재현 문장 없이 고치기부터 시키고, 테스트를 실행하지 않은 채 통과했다고 믿으며, GREEN 단계에서 리팩터까지 한 번에 넣어 diff를 키우는 경우입니다. 아래는 그 세 곳을 끊는 순서입니다.
왜 AI에게는 테스트가 지시서가 되나
사람 개발자는 암묵적 맥락을 기억합니다. AI는 그 맥락을 매번 컨텍스트 안에서 추론해야 합니다. 좋은 테스트는 지금 실패하는 조건, 기대 동작, 지켜야 할 계약, 변경 범위를 알려 줍니다. 테스트는 AI에게 주는 가장 구체적인 작업 지시서입니다.
| 단계 | 의미 | AI에게 시킬 일 |
|---|---|---|
| RED | 실패 테스트를 먼저 만든다 | 문제를 재현하는 테스트 작성 |
| GREEN | 최소 수정으로 통과 | 가장 작은 변경 |
| REFACTOR | 통과 후 구조 정리 | 중복 제거, 이름 정리 |
| REPORT | 증거를 남긴다 | 명령, 결과, 남은 위험 |
버그 설명을 사용자 행동으로 바꾼다
「목록이 이상해요」는 범위가 흐립니다. 「공개 글 5개만 보여야 하는데 draft가 같이 노출된다. draft는 목록과 sitemap에서 빠져야 한다」처럼 재현 문장으로 바꿉니다.

RED가 실제로 실패하는지 확인한다
테스트를 작성만 하고 실행하지 않으면 의미가 없습니다. 반드시 한 번 실패 로그를 봅니다. 처음부터 통과하는 테스트는 문제를 재현하지 못한 것입니다.
⚠️ 주의: AI가 「테스트도 같이 고쳐서 통과」시키려 하면 RED가 무너집니다. 실패 로그를 남긴 뒤에만 구현을 허용하세요.
GREEN에서는 최소만 고친다
통과에 필요한 가장 작은 diff만 허용합니다. 「관련 파일도 정리」는 이 단계가 아닙니다. 테스트가 통과한 뒤에야 구조를 건드립니다.
REFACTOR는 초록불 이후에만
중복 제거와 이름 정리, 범위 축소는 통과 이후에만 합니다. 리팩터 중 테스트가 깨지면 그 커밋은 롤백 후보입니다.
AI에게 줄 때 자주 깨지는 프롬프트
나쁜 예: 버그 고쳐줘. 좋은 예: 아래 테스트를 먼저 실패시킨 뒤, 그 테스트만 통과하는 최소 수정을 하고, 리팩터는 통과 후에만 해. 테스트 파일을 통과시키기 위해 기대값을 바꾸지 마.
💡 Tip: 프롬프트에 「기대값을 바꿔 통과시키지 말 것」을 명시하세요. AI가 테스트를 약화하는 경우가 있습니다.
공개 전에 남길 증거
실행한 명령, 실패/통과 로그, 변경 파일, 남은 위험을 짧게 남깁니다. 「된 것 같다」로 끝내지 않습니다.
어떤 테스트를 고를지
증상이 UI에만 보이면 컴포넌트 테스트나 통합 테스트가 재현에 유리합니다. API 계약이 깨졌다면 핸들러 단위 테스트가 빠릅니다. 결제나 배포처럼 공개 경로가 위험하면 마지막에 smoke E2E를 한 번 둡니다. 처음부터 E2E만 고르면 피드백이 느려 AI가 추측으로 넓게 고치기 쉽습니다.
확인: 지금 고칠 증상을 가장 싸게 실패시키는 계층을 골랐는지 한 줄로 말할 수 있어야 합니다.
실제로 돌려 본 짧은 시나리오
공개 목록에 draft가 섞여 보이던 경우, 먼저 「draft는 목록에 없어야 한다」는 테스트를 작성해 실패 로그를 받았습니다. AI에게는 그 로그만 주고 최소 필터 수정을 요청했습니다. 통과 후 sitemap 제외는 별도 RED로 나눴습니다. 한 번에 「목록이랑 사이트맵이랑 robots까지」를 맡기면 diff가 커지고 롤백이 어려워집니다.
플래키한 시간 의존 테스트는 GREEN 판정에 쓰지 않습니다. 시계를 고정하거나 네트워크를 스텁한 뒤에야 신뢰합니다.
팀에서 합의할 한 줄 규칙
「구현 전에 실패 로그를 붙인다」를 PR 템플릿에 넣으면 습관이 유지됩니다. 실패 로그가 없는 AI 코딩 PR은 리뷰를 시작하지 않습니다. 이 규칙만으로도 「된 것 같다」로 머지되는 사고가 줄어듭니다.
출처와 링크
- Testing Library guiding principles
- Jest Getting Started
- Kent C. Dodds Write tests
- GitHub Actions 워크플로 문법
조사 기준: 2026년 7월. 프레임워크별 러너는 프로젝트에 맞게 고르고, 순서(RED-GREEN-REFACTOR)만 고정합니다.
자주 묻는 질문
테스트가 없는 레거시에서도 이렇게 하나요?
네. 전체 커버리지를 먼저 채우지 말고, 지금 고칠 증상만 재현하는 테스트 한두 개부터 둡니다. 그 테스트가 RED인지 확인한 뒤 구현합니다.
E2E만 있으면 충분한가요?
증상 재현에는 E2E가 강력하지만 느리고 불안정할 수 있습니다. 가능하면 단위/통합으로 실패를 좁히고, 공개 경로는 smoke로 보완하세요.
AI가 테스트 기대값을 바꿔 버리면?
프롬프트에 기대값 변경 금지를 넣고, 리뷰에서 테스트 diff를 먼저 보세요. 기대값이 바뀌었으면 구현이 아니라 계약이 깨진 것입니다.
GREEN에서 리팩터를 같이 하면 안 되나요?
같이 하면 실패 원인이 구현인지 구조 변경인지 구분되지 않습니다. 통과 후에만 리팩터하세요.
플래키 테스트는 어떻게 하나요?
시간/네트워크 의존을 줄이고 재현 가능하게 고칩니다. 불안정한 테스트를 기준으로 GREEN을 판정하지 마세요.
문서화는 어디까지 남기나요?
실행 명령, 실패와 통과 로그, 변경 파일, 남은 위험이면 충분합니다. 장문 회고보다 재실행 가능한 증거가 중요합니다.
Related terms
본문과 함께 보면 좋은 사전 용어
테스트를 실행하기 전에 준비해 두는 고정된 데이터나 상태를 말한다. 예를 들어 테스트용 사용자, 샘플 주문, 권한 조합, 고정 날짜 같은 입력을 매번 같은 형태로 만들면 테스트가 재현 가능해진다. 바이브 코딩에서는 AI가 임의의 예시 데이터로 기능을 통과시킬 때가 많으므로, 픽스처를 명확히 정의해 어떤 데이터로 검증했는지 남겨야 실패를 다시 만들고 원인을 추적하기 쉽다.
프롬프트 엔지니어링프롬프트 템플릿반복해서 쓰는 AI 작업 지시를 일정한 칸으로 나누어 재사용하는 프롬프트 형식이다. 초보자는 매번 즉흥적으로 '이 기능 만들어줘'라고 쓰기보다, 목표, 현재 파일, 입력 자료, 제약 조건, 원하는 출력 형식, 검증 방법을 같은 순서로 채우면 AI가 누락 없이 코딩 작업을 수행하기 쉽다. 특히 VIBE 코딩에서는 템플릿이 작업 범위를 고정하는 안전장치가 된다. 예를 들어 버그 수정 템플릿에 재현 단계, 기대 동작, 실제 동작, 실패한 테스트, 수정 금지 파일을 넣으면 AI가 엉뚱한 리팩토링으로 번지는 일을 줄일 수 있다. 좋은 템플릿은 길기만 한 문서가 아니라, 사람과 AI가 함께 확인해야 할 결정 지점을 빠뜨리지 않게 해주는 체크리스트에 가깝다.
프롬프트 엔지니어링출력 형식AI가 답변이나 코드를 어떤 구조로 내야 하는지 미리 정하는 규칙이다. 초보자는 '설명해줘'보다 '수정할 파일, 이유, 코드 변경, 테스트 명령, 남은 위험 순서로 답해줘'처럼 출력 형식을 지정하면 결과를 훨씬 쉽게 검토할 수 있다. VIBE 코딩에서 출력 형식은 사람의 리뷰 시간을 줄이는 품질 게이트다. 예를 들어 JSON, 표, 체크리스트, 단계별 목록 중 무엇이 필요한지 정하면 AI가 장황한 설명으로 핵심을 숨기거나, 코드만 던지고 검증 방법을 빼먹는 일을 줄일 수 있다. 자동화 파이프라인에서는 특히 정해진 형식이 중요하며, 형식이 어긋나면 후속 스크립트나 테스트가 실패할 수 있다.
Useful links
실제로 이어서 열어볼 즐겨찾기
쉬운 보안을 지향하는 한국어 보안 계정으로, AI·VIBE 코딩 흐름에서 놓치기 쉬운 보안 감각을 되짚는 데 유용합니다.
VIBE 코딩 레퍼런스웹사이트 해부도 · Website Anatomy MapAI와 웹사이트를 함께 만들 때 ‘그 부분’이 아니라 정확한 UI·웹 용어로 지시할 수 있게 돕는 영-한 시각 사전입니다.
VIBE 코딩 제품 리서치Killed by Google · Google GraveyardGoogle이 종료한 서비스와 제품을 한눈에 모아, 플랫폼 의존성과 제품 지속성 리스크를 판단하게 해 주는 ‘Google 묘지’ 아카이브입니다.
다음 학습
같은 섹션에서 이어 읽기 좋은 콘텐츠
바이브코딩으로 애드센스 부업 시작할 때 | 회원/결제 없이 먼저 막는…
바이브코딩으로 「부업 사이트」를 만들 때 첫 프롬프트가 자주 이렇게 나갑니다. 회원가입, 문의폼, 결제, 관리자 대시보드까지 한 번에. 화면은 빨리 나오지만, 그 순간부터 주문/환불/고객 DB/API 키/로그에 쌓인 이메일이 운영자 책임이 됩니다.
애드센스 부업의 본체는 상품을 직접 파는 일이 아닙니다. 유용한 콘텐츠로 방문을 모은 뒤, 광고 지면으로 수익을 받는 간접 수익화입니다. Google이 광고 매칭과 정산을 담당하고, 게시자는 콘텐츠/정책/트래픽 품질을 지킵니다. (How AdSense works)
읽는 데는 약 10분이면 됩니다. 첫 세션에서 실제로 손댈 일은 「무엇을 빼고, 무엇을 고지하고, 어디에 비밀을 두지 않을지」입니다…
애드센스 심사 전 PSI 체크리스트 | 점수 배점부터 알고 고치기
PSI를 켰는데 점수가 안 움직이면, 대개 고치는 순서부터 틀린 겁니다. 이미지를 압축하고 폰트만 만지는데도 성능이 제자리라면, 점수 배점과 가장 무거운 지표를 먼저 안 본 경우가 많습니다. 애드센스 심사 전 점검은 "체감상 느린 것"이 아니라 "점수에 바로 들어가는 항목"부터 봐야 합니다.
특히 광고가 붙는 사이트는 속도 최적화 글의 조언을 그대로 따라가면 더 망가질 수 있습니다. 대표적인 게 광고 스크립트를 무조건 늦게 넣는 방식입니다. Auto ads나 크기 미지정 반응형 광고가 있으면 오히려 CLS와 수익이 함께 흔들릴 수 있습니다. 그러니 이 글은 폰트 회고가 아니라, 애드센스 심사 전 하루에 끝내는 PSI 체크 순서를 다룹니다.
준비물은 세 가지면 됩니다. 홈/대표 글/목록 URL 하나씩, PSI 모바일 랩 실행 결과, 그리고 "오늘…